사내에서 테스트 커뮤니티 매체를 만들고 있는데,
테스트성으로 만든 매체다보니,
커뮤니티의 게시글을 검색하는 API에서 Like '%검색어%' 절로 간단하게 작성해 놨다.
그러다 보니 트래픽이 분당 500~700 사이었는데도 불구하고 RDS의 cpu가 항상 95~98%로 상당히 많은 부하가 있었다.
어찌 보면 당연한 결과다.
like절은 인덱스를 타지 않고 기본적으로 풀스캔으로 동작을 하게 된다.
데이터는 약 16만 건의 row가 있었다.
EXPLAIN
SELECT *
FROM contents c
WHERE title LIKE '%검색어%';explain으로 쿼리 전략을 살펴보면

모든 row를 스캔하고 그 대상은 약 13만 건의 데이터임을 알 수 있다.
사용자가 실제로 분당 30~40건의 검색 API를 호출했고, 호출마다 13만건의 데이터를 스캔했으니 DB가 멀쩡했을 리 없다.

DB가 죽여줘... 를 외치고 있었다...
이 과정에서 경험해보지 못했던 ElasticSearch를 도입해 볼까? 란 생각도 했었지만,
테스트성으로 만든 프로젝트고 시간 여유가 없어 적용하지 못했고,
트래픽을 견딜만한 문제 해결방법은 필요헀던 시점이었다.
팀원들끼리 논의한 결과 MySQL의 Full Text Search라는 게 있다는 의견이 나왔고, 이를 바로 적용해 보기로 했다.
FullText Search란?
공식문서에는 기본적으로 하나 이상의 컬럼의 집합을 통해 자연어를 검색하는 인덱싱 방법이다.
인덱싱을 설정한 컬럼에 검색어로 주어진 문자열이 얼마나 일치하는가에 따라 해당 row를 반환한다.
일치율이 높을수록 1이상의 수치에 수렴하고, 0에 가깝다면 주어진 문자열이 해당 row에 포함되지 않음을 의미한다.
Full-text index는 FULLTEXT 타입의 인덱스이며 varchar, Text 데이터 타입에 지원된다.
인덱스를 추가하려면
//테이블 생성시,
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body)
//기존 테이블에 인덱스 추가시,
CREATE FULLTEXT INDEX ft_index ON articles (title,body)위와 같은 쿼리를 실행하면 된다.
SELECT id, MATCH (title,body)
AGAINST ('Tutorial' IN NATURAL LANGUAGE MODE) AS score
FROM articles;예를 들어, 위와 같은 쿼리가 있다고 가정하면 articles라는 테이블에 Tutorial이란 문자열이 포함된 row의 일치율을 보여준다.
문법은 Match({인덱싱된 컬럼}) AGAINST ( '{검색할 문자열}' {검색 Mode정의} )와 같이 사용된다.
위 쿼리를 해석하면 'articles테이블에 Tutorial이란 문자열이 포함된 row를 자연어 모드로 검색하여 일치율을 반환'이다.
문법에서 검색 Mode정의는 생략할 수 있다. (생략한다면 기본 전략은 자연어 검색 모드다.)
제한사항
공식문서에서 더 많은 자료를 참고할 수 있습니다.
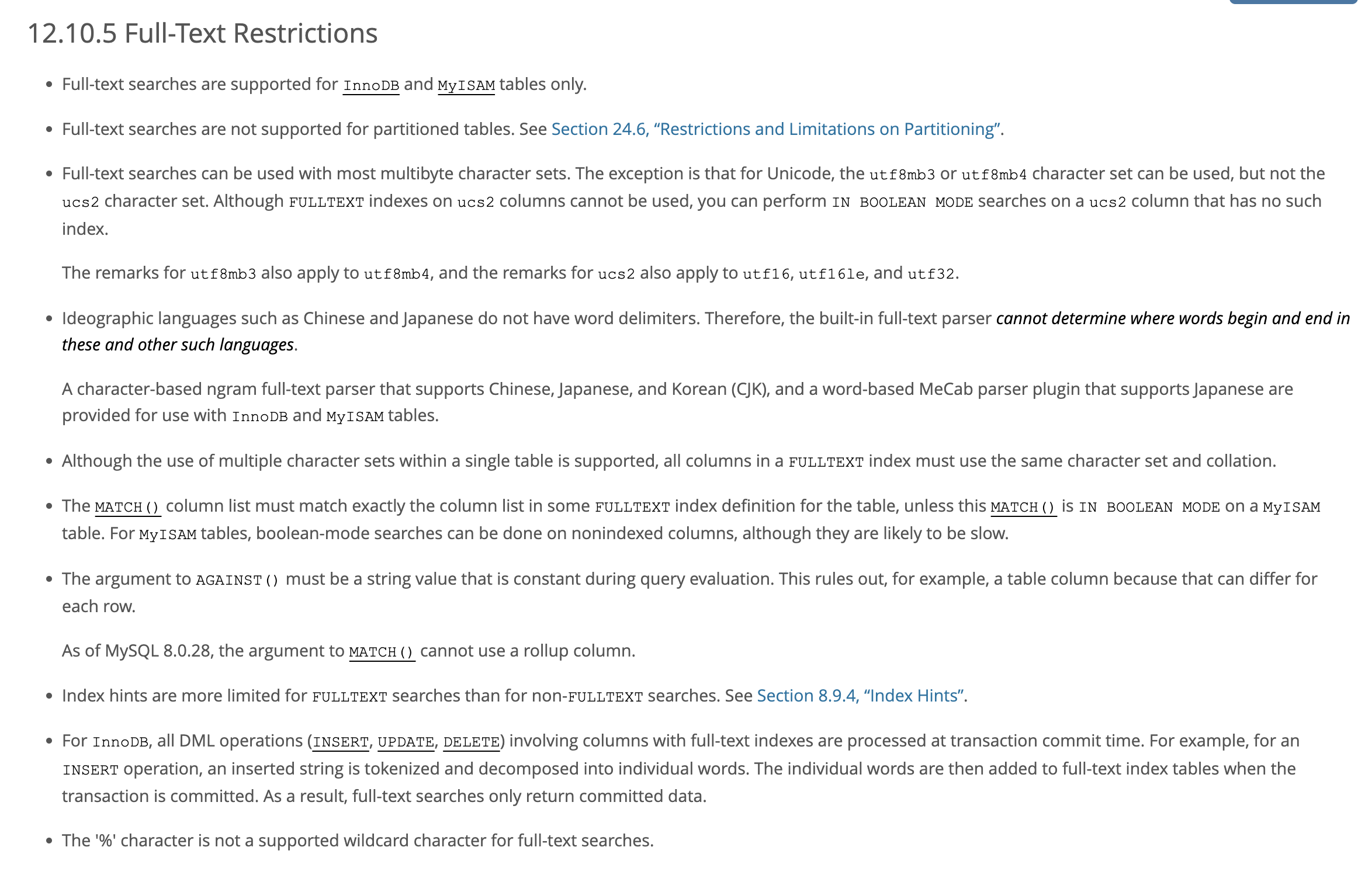
Full-Text Stopwords
FullText search에서 사용 전 주의사항은 MySQL에서 정의한 예약어와 같은 stopword란 개념이 있는데, stopword에 지정된 단어가 검색어로 주어질 경우 잘못된 조회 및 결과 누락이 발생할 수 있다.
불용어 목록 확인하기
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;
검색 모드의 종류
1.Boolean Full-Text Searches
Bool 검색은 특정 단어의 포함, 미포함 조건을 설정할 수 있다.
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);위와 같은 쿼리가 있다고 가정하면 articles 테이블에서 title, body 칼럼에서 MySQL은 포함하지만 YourSQL은 포함하지 않는 문자열을 가진 row를 반환한다.
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('SQL* -YourSQL' IN BOOLEAN MODE);예시 2번째로는 *(와일드카드)도 사용가능한데 위 쿼리의 해석은 SQL~을 포함하는 모든 문자열이지만 YourSQL은 포함하지 않는.이라는 의미다.
실제로 Like 절과 상당히 유사하게 사용할 수 있다.
다만 눈에 띄는 특징이 있다면

연관성에 대해 정렬하지 않고, FULLTEXT인덱스 없이도 동작하지만 상당히 느리다고 표현되어 있다.
더 자세한 자료는 공식문서(Boolean Full-Text Searches)에 더 많은 자료가 있습니다.
2.Full-Text Searches with Query Expansion
쿼리 확장 질의 방법이다.
이 방법은 꼭 특정 검색어가 컬럼에 포함되지 않더라고 연관이 있을법한 row를 같이 반환해 준다.
(실제로 사용해 본 결과 한국어 검색보다 영문 검색이 더 결과가 많이 나오고 정확하다.)

공식문서에서 보여주는 예제를 보면 실제로 id가 4인 row는 database가 포함되지 않았지만 연관된 MySQL이 포함되어 반환된 것을 볼 수 있다.
이 쿼리를 적용해 보고 검색 API에서는 Like절과 원하는 검색 결과 및 반환 row수가 일치하지는 않았지만 연관된 데이터가 더 많이 나왔다.
즉, 예상치 못한 데이터가 나올 수도 있다는 말이다.

또한, 사용자가 검색어에 오타가 발생했을 시, 비슷한 단어가 포함된 row도 반환해 준다.
예상치 못했던 문제들
위와 같이 인덱스도 적용을 해보고 실제 쿼리 속도도 약 100배 이상 빨라졌지만, 앞서 언급했듯이 Like절과 검색 결과에서 차이가 발생했다.
즉, 누락된 결과가 발생했고 이는 내가 의도한 검색 API가 아니었다.
그러다가 찾은 게 ngram parser였다.
ngram parser를 이용하면 예상치 못한 누락 건 없이 Like절과 동일하게 데이터를 검색할 수 있다.
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;
# Or:
CREATE FULLTEXT INDEX ft_index ON articles (title,body) WITH PARSER ngram;인덱스 추가 시, with parser ngram을 추가해 주면 된다.
공식문서에 더 많은 자료가 있습니다.
ngram parser는 검색어를 토큰화하여 검색하여 다른 방법보다 속도를 높일 수 있다.
한국어, 중국어, 일본어 등을 지원하여 내가 딱 찾던 검색 방법이다.
참고 :

실제 검색 속도 비교

위 이미지에 해당하는 쿼리는
SELECT *
FROM contents c
WHERE title LIKE '%검색어%';와 같다.

13만 건의 데이터 검색 시 2분 25초 정도가 소요됐다.
그러나
SELECT *
FROM contents c
WHERE MATCH(title) AGAINST('검색어*' IN BOOLEAN MODE);
ngram parser로 인덱싱 된 검색 결과는 2초밖에 안 걸렸다.
약 98%의 성능 향상이 있었다.
그러나 이 Ngram parser 조차도 제한사항이 있었는데 최대 검색글자가 단일 문자열 검색 시 2글자였다.

SHOW VARIABLES WHERE variable_name = 'ft_min_word_len';위 쿼리를 검색해 보면

기본적으로 4로 설정되어 있을 것이다.
이 의미는 4글자로 토큰화하여 검색한다는 뜻이며 이 수치를 낮춰야 2글자 검색이 가능하다.

AWS RDS에서는 파라미터 그룹에서 ft_min_word_len를 2로 설정하고 적용 후, 다이나믹 옵션이 아니기 때문에 DB의 재부팅이 필요하다.

값이 만약 잘 바뀌었다면 2글자 검색어도 충분히 검색할 수 있다.
만약 RDS를 사용하지 않는 경우,

설정파일에서 이와 같이 설정 후, 재부팅을 해주면 된다.
'DataBase' 카테고리의 다른 글
| SQL] 쿼리로 페이지네이션 하는 방법 (페이징) (0) | 2021.08.04 |
|---|---|
| Error] Could not create connection to database server. (0) | 2021.04.13 |
| 인덱스에 대해서 알아보자 (0) | 2021.02.15 |
| 쿼리 속도 향상을 위한 방법들 (1) | 2021.02.14 |
| MySQL]The MySQL server is running with the --read-only option so it cannot execute this statement (0) | 2021.02.08 |
댓글