기존에 사용하기로 생각만 했던 JPA.
회사에서 작은 웹 크롤링 API 서버를 만들 일이 생겨서 간단하게 사용해봤다.
JPA는 Java의 ORM(Object Relation Mapping) 표준 기술로 인터페이스이다.
구현체는 스프링 부트에서는 기본적으로 하이버네이트이다. (바꾸거나 직접 구현할 수 있다.)
JPA는 Java 웹 앱과 JDBC 사이에서 동작하며 개발자가 SQL에 대한 종속성을 낮출 수 있게 해 준다.
(다만 JPA의 표준을 따라야 해서 러닝 커브가 있다.)
오늘은 실제 사용한 코드를 보며 설명을 이어간다.
과거엔 xml로 설정을 했었지만 spring boot에선 간단하게 사용이 가능하다.
일단 JPA 사용을 하기 위해
implementation 'org.springframework.boot:spring-boot-starter-data-jpa:2.5.6'을 build.gradle에 추가해준다.
그다음

메인 클래스에 @EnableJdbcRepositories 어노테이션을 붙여준다.
이렇게 되면 JPA 사용이 가능하다.
엔티티에 어노테이션들을 붙여야 하는데 나의 ERD는 아래와 같다.
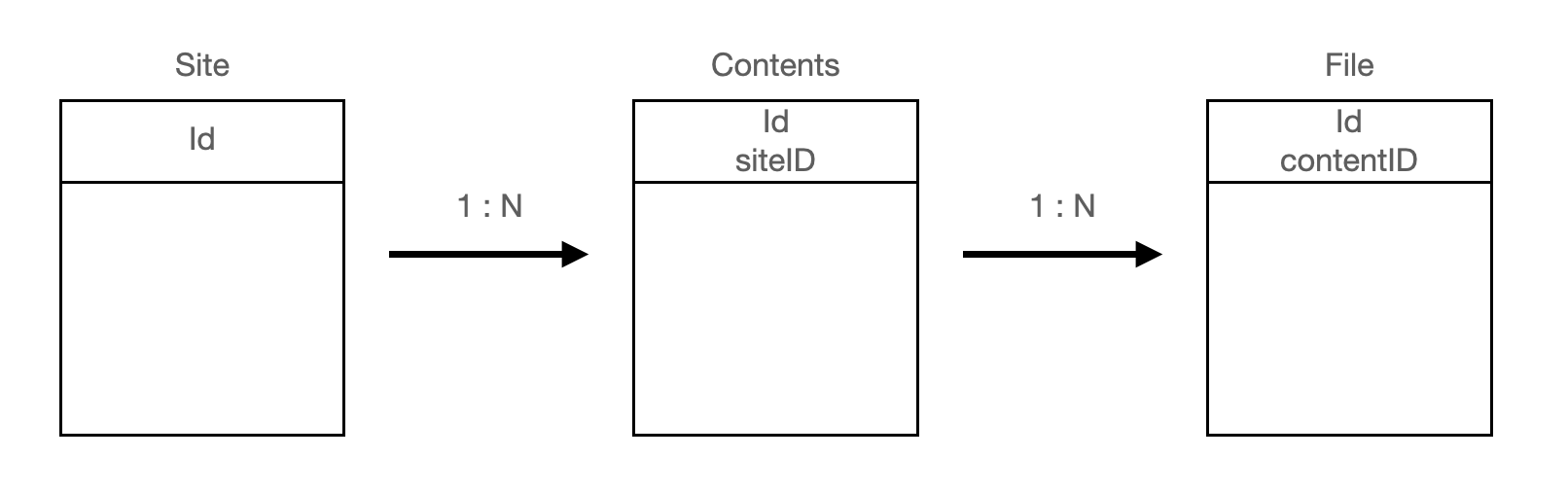
사이트 > 콘텐츠 > 파일 순으로 하향식 구조를 띄며, 1대 N 관계를 가지고 있다.
Site 엔티티를 보자.

@Id
@Column(name = "id", nullable = false)
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;@Id는 PK 항목이다.
테이블 옵션과 일치시켜주면 되고, @Column 항목을 통해 특정 테이블에 칼럼과 매치시킬 수 있다.
@GeneratedValue(strategy = GenerationType.IDENTITY)는 자동으로 항목이 생성된다는 의미고
MySQL의 AI와 같다.
@Column(name = "domain", nullable = false)
private String domain;
@Column(name = "category", nullable = false)
private String category;아래 다른 칼럼들도
@Column(name = "{칼럼 이름}", nullable = false) 어노테이션을 통해 특정 칼럼을 매핑시켜주고, null이 가능한지 설정한다.
그리고 아래에 연관 관계 매핑에 중요한 정보가 있다.
@OneToMany
@JoinColumn(name = "site_idx")
List<Content> contents;@OneToMany는 아까 ERD에서 봤듯이 1:N 관계이기 때문에 해당 어노테이션을 붙여줬고
Content 엔티티에 조인할 키 값을 설정해주면 1 : N 관계로 매핑이 가능해진다.
하위 엔티티들은 이하 동일하므로 사진만 첨부하도록 한다.
@Component
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity(name = "content")
public class Content {
@Id
@Column(name = "id", nullable = false)
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column(name = "site_idx", nullable = false)
private int siteIdx;
@Column(name = "title", nullable = false)
private String title;
@Column(name = "content", nullable = false)
private String content;
@Column(name = "url", nullable = false)
private String contentURL;
@Column(name = "is_delete")
private int isDelete;
@OneToMany
@JoinColumn(name = "content_id")
private List<File> files;
}Content.java
@Component
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity(name = "file_info")
public class File {
@Id
@Column(name = "id", nullable = false)
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column(name = "content_id", nullable = false)
private int contentId;
@Column(name = "file_path", nullable = false)
private String filePath;
}
File.java
JPA의 본격적인 사용
일단 JPA를 통해서 데이터를 가져오기 위해 인터페이스를 구현한다.
@Repository
public interface ContentRepository extends JpaRepository<Content, Integer> {
List<Content> findAll();
List<Content> findAllByIsDelete(int isDeleted);
Content findById(int id);
List<Content> findContentsByTitleIsContaining(String title);
}
@Repository는 스프링 빈 등록을 위해 붙여주고,
JpaRepository<Content, Integer> 를 상속받아 준다.
첫 번째 항목에는 엔티티를 넣어주고, 두 번째는 PK의 자료형 Wrapper Object를 적어준다.
List<Content> findAll(); // 리턴 자료형과 모두 찾는 APIfindAll()은 SELECT * FROM Content와 같다.
그리고, 칼럼들을 인식해서 다양한 메서드를 제공하는데

이런 자동완성을 제공한다.
키워드는 쿼리에 따라 너무 많아서 위 링크를 참고 바란다.
그리고 컨트롤러 통해서 해당 메서드를 호출하게 되면

이런 식으로 리턴이 잘 된다.
'Java' 카테고리의 다른 글
| Java 회전된 문자열인지 확인하기 (0) | 2022.01.30 |
|---|---|
| Log4j 보안 이슈 (0) | 2021.12.13 |
| spring,java]스프링 Quartz 스케줄러 사용하기(배치) (0) | 2021.08.18 |
| SpringBoot,React]스프링 실행시 리액트 서버 자동 실행 , 빌드시 같이 빌드하기 (0) | 2021.08.06 |
| java,spring]twilio를 이용해서 전화솔루션 구축하기 (비상연락망) (4) | 2021.06.21 |



댓글